The paper titled “Efficient Streaming Language Models with Attention Sinks” addresses two main challenges in deploying Large Language Models (LLMs) in streaming applications like multi-round dialogues: the extensive memory usage due to caching Key and Value states (KV) of previous tokens, and the limitation of LLMs in handling longer texts than their training sequence length[“].
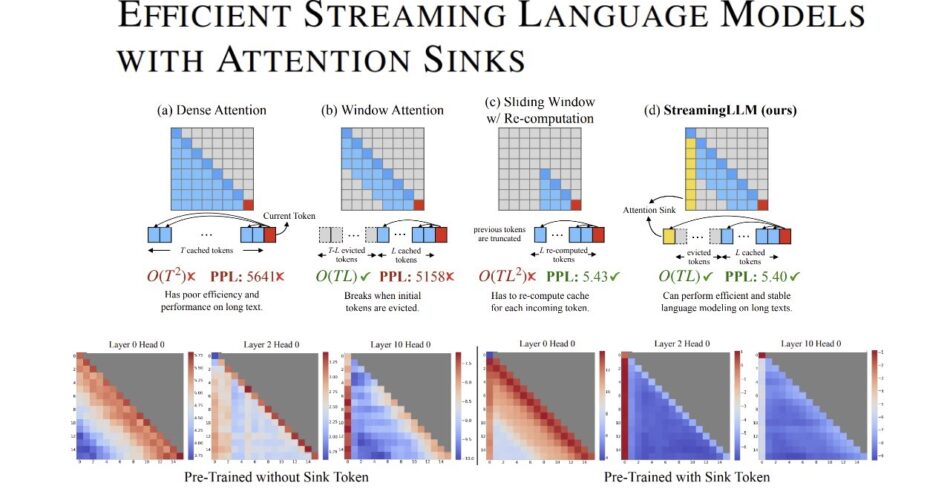
LLMs, essential in various applications, face constraints due to the finite attention window size during pre-training, limiting their effectiveness for longer sequences. The paper introduces the concept of “attention sinks,” where initial tokens, despite lacking semantic importance, collect significant attention scores. This phenomenon is attributed to the softmax operation in autoregressive LLMs, which requires attention scores to sum up to one for all contextual tokens[“].
To address these challenges, the paper proposes StreamingLLM, a framework that allows LLMs trained with a finite attention window to handle texts of infinite length without fine-tuning. This method involves preserving the KV of a few initial tokens (attention sinks) along with the sliding window’s KV, thus maintaining normal attention score distribution and stabilizing model performance. StreamingLLM is shown to be effective for models like Llama-2, MPT, Falcon, and Pythia, handling up to 4 million tokens or more, outperforming traditional sliding window approaches[“].
Additionally, the paper suggests that LLMs can be pre-trained to require just a single attention sink token for streaming deployment, thereby improving efficiency in streaming settings[“].
Source – https://arxiv.org/abs/2309.17453.